ChatGPT等生成系AIの現 ...-ICT技術調査 デジタルヘルス情報提供-株式会社テックナレッジハウス
 BLOG
/ デジタルヘルスの未来
BLOG
/ デジタルヘルスの未来
ChatGPT等生成系AIの現在地と社会的課題 その2 課題と対策
9月の当ブログではChatGPTなどの生成系AIの持つ特徴や現状を簡単に整理した。今回は前回の予告通り、生成系AIの課題を整理した上で、どのような対応や対策が講じられているか、講じられようとしているかをまとめてみたい。IT領域にまで踏み込む説明も一部あるがご容赦願いたい。
生成系AIには、これまでのAIにない素晴らしい機能を持つ一方、前回のブログで指摘したように大元のモデル作成段階にいくつか問題があり、それなりに技術的な解決策があるものから、社会でルール決めをしない限りは社会的問題を引き起こすことまである。AI関係者は、これらの課題を解決して信頼できるAI (Trusted AI) を提供すべく努力している。社会的問題となりうる点については、各国や企業・団体のレベルでの対策検討も進み始めた。
ただ、生成系AIは昨年11月のChatGPTの発表以降に急速に一般の人まで広まったため、対策が後追いである事は否めない。適切なコントロールの下、健全な活用の進むことを望んでやまない。
1.一般的なAI開発と利用の流れ
本ブログをより理解して頂くため、このブログの後半で著作権の説明に使う図をまずここで説明したい。
下の図1では、一般的な生成系AIの開発とその利用の流れが示されている。我々が日常使うChatGPTやStable Diffusion(テキストから画像を生成する分野で著名な生成系AIのツール)は、図1の学習済みのモデルに相当する。これらは図の上半分にあるよう、我々に提供される前に大量の学習用データで長時間の学習が行われる。
一方、実際の利用にあたっては、図の下半分にあるよう、学習済みのモデルに対し、プロンプトなどで入力や指示を行い利用する。
(図1)生成系AIの開発と利用の流れ(一般的な例)
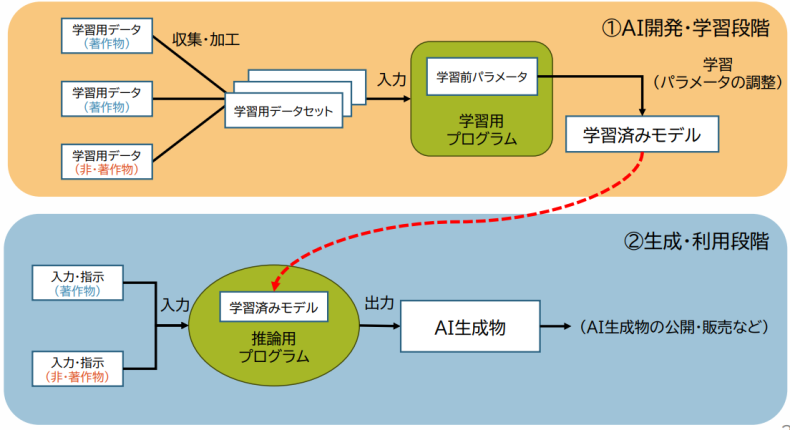
(出典) 文化庁の資料 ”AIと著作権”
2.生成系AIの課題
(1)生成系AIのモデル自身の持つ問題点
生成系AIが事前学習の段階で、通常Wikipedia含めweb上のデータを利用するため、間違いや新しいことを知らない(GPTやChatGPTには2021年9月までの情報しか含まれない)というこれまでのAIとは異なる問題点を抱えている。
(2)生成系AIでの課題
ここでは、生成系AIの課題と認識されている主要な点を整理する。
① 返答に誤りを含む可能性のあること、新しいことに答えられないこと
具体的には以下のようなことがおこる場合がある。
1)答え方はもっともらしいが、学習データによっては間違いが入り込んだり、新しい情報が入っていないことがままある。なお、全く事実とは異なるような答えを出すことをハルシネーションという。
2)バイアスのかかった回答がでることがある。これは、モデル学習の段階で大量のデータを無条件に利用することに起因する。
3)悪用される可能性がある。ハッカーにとり新たなセキュリティ攻撃のデータの生成が簡単になり、これらを利用した攻撃を受ける可能性や、セキュリティ以外では、暴力や性など不適切な内容のアウトプットが誘導されることを利用される可能性もある。
② 情報の取扱いに関しては法律に触れる可能性のある以下のようなことが起こる可能性がある。
1)著作権など知的財産権侵害になりそうなこと
生成系AIで生成した画像などが特定の人の作品に似ている。特に画像の場合に顕著。テキスト系でも小説を書かせるような場合。
2)個人情報や会社の秘密情報の勝手な利用
利用者が生成系AI利用時にプロンプトなどで個人情報や会社の秘密情報を入力した場合に、それらが生成系AIの学習に使われる可能性がある。
③ AIの非透明性
AIに何か問いかけたり依頼した時になぜその結果がでたかがわからない、というAIのロジックに関する非透明性と、提供されたAIのモデルがどんなデータで学習がおこなわれたか、という学習のためのデータソースの不透明性の2つの観点がある。特に生成系AIの場合、大量の事前学習のデータに誤りを含むデータソースを利用するケースが多いので、学習したデータの公開も透明性確保のためには重要となる。
④ 多くのリソースが必要でコストやエネルギー消費が大きくなる
生成系AIの場合、特に事前学習の段階で大量のコンピュータリソースを長時間利用す るため、多額のコストがかかり、その計算により多くのエネルギー消費や多くの二酸化炭素排出を伴う。
3.課題の対策
以上挙げてきた課題に対する対策は、大別して製品の改善やツールの提供による方法と、使い方で規制やルールを設ける方法を併用する必要がある。
① 返答にまつわる諸問題への対策
まず、利用者まで含め、生成系AIの特性・欠点を理解し、利用者が知識の部分は別の情報ソースに頼り、生成系AIでは要約や作文のような人間らしい部分を任せる、とのような方針で生成系AIを使うようにすれば、返答への諸問題の相当数はなくなる。社内の文書に関する処理など特定の領域に限れば限るほどこの指針の効果は大きい。
具体的には、たとえば、図2のようなRAG (Retrieval Augmented Generation) という手法での生成系AI (図2ではLLM) の使い方があり、現在広く使われるようになってきている。
(図2)知識の部分は生成系AI (LLM) に頼らないLLM利用法のRAG
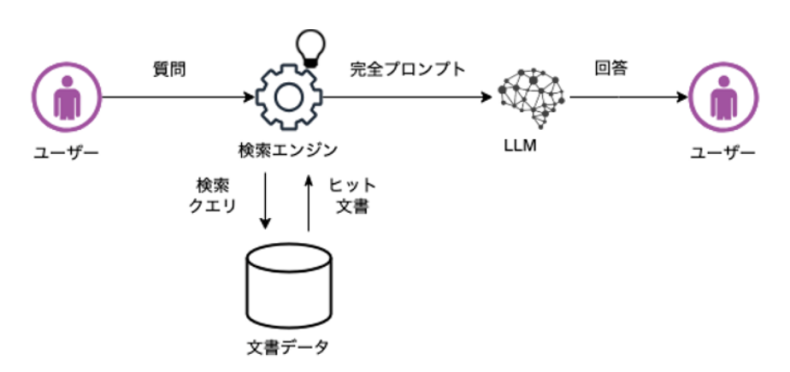
(出典)Retrieval-Augmented Generationシステムの改善方法の紹介
これと同時に、生成系AI自身でも変な答えの出ないような改良を進めるほか、外部の生成系AIを利用するSaaSでは、生成系AIを呼び出してアウトプットが返ってきたら、このアウトプットを独自にチェックするようになってきているし、アプリケーションから外部の生成系AIを利用した時に返答をチェックするサードパーティの製品もでてくるようになった。
また、ビジネスや研究利用で分野に特化したモデルの場合は、そもそも誤りがあることが許されないので、図1の学習用データそのものから見直した学習を行う。実際に、Googleは医療向け生成系AIモデルとしてMed-PaLM2や金融業界向けにはBloombergGPTがある。
② 法律に触れそうな問題への対処とより広い社会への影響への対処
法律に触れそうなこと含め、生成系AIを使うことによりおこる社会や組織内での問題に対しての国・地域や会社・団体での対応の状況を説明したい。
1)著作権や個人情報/機密情報の無断利用の関係
実際には、著作権がからむケースは下記のように3つの局面がある。既出の図1を参照しながら見て頂ければわかりやすいと思う。
・生成系AIのモデル作成用の学習データに著作権がらみのデータが入っている。
・生成系AIのモデルが画像などを作成したときに著作権にひっかかりそうな画像などを作成してしまう。
・生成系AIが作成した画像の扱い、つまり著作権の対象かどうか
日本では、著作権を主管している文化庁が、生成系AIと著作権についての見解を出している。これによれば、上記のそれぞれの局面で、こうだ、といいきれる回答はなく、著作権に引っかかることもあるので、現行の法律に従って判断してほしいといっている。
また、利用時にプロンプトの形式などで入力される情報は、ChatGPTが出た当初は学習に利用されるという状況だったが、今では、利用時に入力した情報は生成系AIの学習に利用しない、もしくはオプションで開始時に選択する、などのように進化してきている。
画像生成AIのツールを扱うベンダーでは、以上の様な係争を避けるため下記の様な試みが行われている。
・AdobeはFireflyという画像生成ソフトウェアを提供しているが、このサービスに画像を提供したクリエータに報酬を支払うと発表した。
・ゲッティという画像提供会社は、画像生成AIツールを提供するにあたり、学習に使われた画像の創作者に補償金を払うと発表した。
2)生成系AIの取扱い全般のルール策定への動き
– 国・地域のレベルでは、EUは真っ先に今年の6月にAI規則案を批准した。施行は早くて2024年といわれるが、生成系AI基盤モデル(LLMなどのこと)提供ベンダーに対して、開発段階からライフサイクルでのリスク削減、及び適切なデータガバナンス対策(特に学習するデータのデータソースにつき、適切でなおかつ潜在的バイアスを緩和したデータを利用)を行うことを求めている。
– 民間の日本ディープラーニング協会は、5/1に生成系AIの利用ガイドラインを発表し、下記の様な点を解説している。
・民間企業や各種組織が生成系AIを利用する際に最低限ガイドラインとして定めるべ きこと。
・具体的には、入力するデータの内容や生成物の利用方法によっては法令違反や他社の権利を侵害したりする可能性。
– 日本の大学も、今春多くの大学が生成系AIに対する見解の発表をはじめた。東京大学は、4/3に何ができるかと課題を挙げた上で、学究機関としてよい利用方法を見出していくべきと副学長名で発表している。
– 国際的な生成系AIの取り決めは、G7で国際的取決めを作ることで2023/5に合意された。欧州は上述の規制案ベース、米国が現行法範囲内でという考えで欧米で基本方針に隔たりがある。この中で、日本が全体をとりまとめたいという意向を岸田首相は表明している。
③ AIの非透明性への対応
生成系AI特有の透明性の問題については、データについては以下のような解決策が講じられつつある。結果を導くロジックについては、生成系AIに限らない深層学習一般でAIの出した結果含めて、その解明の研究が行われ、解明のためのツールも出始めているが、まだまだ完全ではない。
1)テキストの生成の分野での答えの情報ソース
一般的には情報ソースは表示されない。
ChatGPTである質問をしたときに、複数のデータソースの情報をまとめて答えてくれるが、そのデータソースは提示されないし、2021年9月以前のことは答えられない。(マイクロソフトのブラウザからAIの入ったBing検索(ブラウザの右上のbをクリックして起動)を行なえば、データソースは表示される。このBing検索では、サマライズや作文もできるようになっている。)
なお、GoogleのBardでは、最新の情報まで含めて答えてくれるが、データソースは表示されない。
創作に関わらない場合は、情報ソース開示の方向で進むだろうが、文学作品のような創作に関わると事情は異なり、この下で述べる画像の対応と同様に考えられる。
2)画像生成
画像生成の成り立ちをトレースする技術の開発が少しずつ進みつつある。
Googleは、法人向けのクラウド上での画像生成(Imagen)サービスに電子透かし機能を追加した。オプションで透かしをいれると、本物と偽装されている場合に識別したり、著作権の保護に役立てることが期待される。但し、今のところ、このImagenの世界の中だけの機能である。
3)データの公開
オープンにするデータセットを作ってから事前学習させたり(RedPajamaなど)、オープンソースのデータセットを使って学習する(DatabricksのDolly2.0など)などの動きもでてきている。
④ リソースの消費をおさえる策
OpenAIやGoogleの大規模な生成系AIにかわり、規模を1桁とか大幅に下げても、特定の専門領域では大規模な生成系AIのモデルより性能が優れる、というようなモデルの開発・研究も進みだした。
日本の例では、たとえばNECは7月に、このような独自モデルを発表した。既に各業種の代表的企業や団体と組んで、専門分野のモデル開発に取り組んでいる。
因みに、医療分野では、国立国際医療研究センターの協力を得て進めているようだ。
以上、生成系AI利用に伴う様々な課題とその対策につき触れてきたが、関係者で協力してこれら課題を乗り越え、生成系AIの利点を活かしたAIの次の段階の未来が拓かれることを切に望んでいる。
- PROFILE
-

柴柳 健一
大手ITベンダーでの海外ビジネス、アライアンス事業の経験を活かし米国最先端ICT技術の動向調査、コンサルを行っている。
- CATEGORY